I’ve been doing some research into carbon aware computing, and I’m trying to find a memorable way to talk about the choices available to you when you want to deploy computing resources in a responsible way, but can not change the underlying code of the application. This post summarises a couple of recent papers, and adds some of my own commentary.
This slide from a recent deck about Ecovisor, A Virtual Energy System for Carbon-Efficient Applications is one I found really helpful for shaping my thinking. The paper with the same name is also worth a read, but it doesn’t share this same presentation of the ideas in this fashion, so I’m posting it here too:
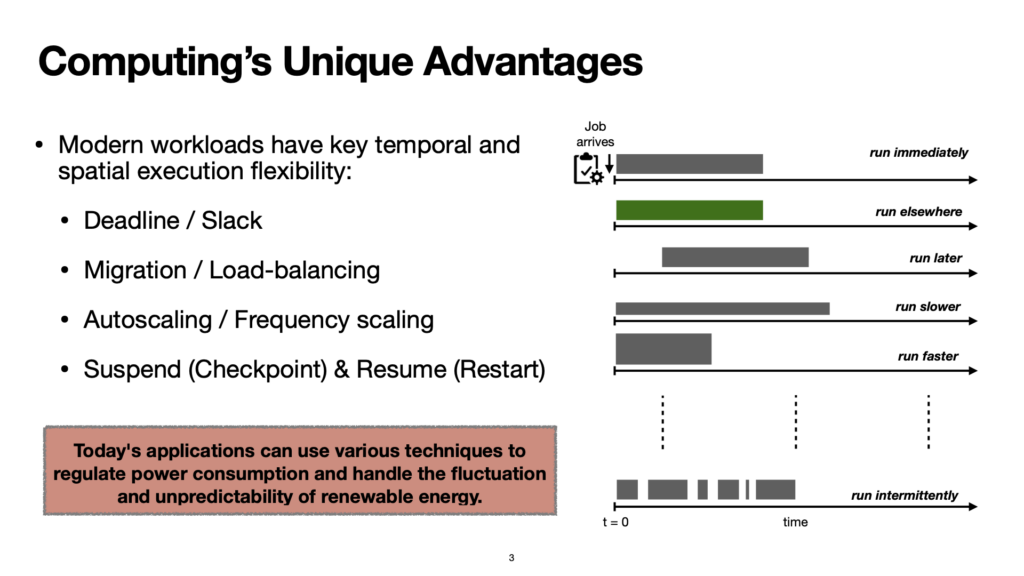
In particular, I want to draw your attention to the 6 responses outlined in the slide, as I haven’t seen them descrtibed like that before:
Run immediately: this is the default. A job comes into the system, and we schedule it on whichever computer has the resources available.
Run elsewhere: this is what some people refer to as spatial migration. You can run the same job where the energy is greener (i.e. Montreal in Canada, or Iceland, or France, or maybe even Kenya).
Run later: this is what some others call temporal migration – because the carbon intensity of electricity changes at different times of day (you’ll have more solar power when the sun us in the sky), you can acheive savings by timing your job to coincide with these periods of low carbon intensity, where more power is coming from cleaner generation. If you can start and finish the job inside the low carbon period, your job’s carbon footprint will be lower.
Run slower: this isn’t really spoken about too much, but it’s useful to know that lots of computers can control their own clock speed. This is often what happens under the hood when you have a machine running on a battery instead of mains power – the machine might prioritize battery life over CPU cycles, and dial own the clock speed accordingly. If the carbon intensity is high, one option available is to scale down the clock speed to do more work in the same time. Conceptually, I think of this like lifting my foot off the accelerator in a manual internal combustion engine car. Taking this car analogy further, in some cases you can control the number of cores you might allocate, to use less power. This is a little bit like how some cars can control how many cylinders they use for fuel efficiency.
Run faster: conversely, if you’re in a period where the carbon intensity of electricity is lower, you could increase work you choose to do during that time, to catch up on a backlog that might have built up when being more frugal with compute resources. Lots of CPUs have support for temporary “burst” mode these days, and while you might not control it directly, this is sometimes what happens under the hood when there is some intense computation to carry out. I conceptualise this like stepping on the accelerator to increase the RPM in a car engine with manual car, (or as an inversion of the paragraph above, going back to using more of the engine’s cylinders to favour power output over fuel efficiency).
Run intermittently: finally, in some cases you’ll want a computing job to be low carbon, but it’ll be too big to do in one go, so you won’t be able to complete it in a single low carbon period. At this point, you might choose to pause, and set a checkpoint, then wait for the next period of low carbon intensity to come, at which you resume it computation from the checkpoint.
A recent paper from the same poeple at Hotcarbon 2023 conference tries another approach at reformulating the options, so they’re easy to remember. It also does a good job of making explicit that each of these have tradeoffs, the more you do them:
There has been a recent focus on exploiting the flexibility of computing’s workloads – along temporal, spatial, and resource dimensions – to reduce carbon emissions, which comes at the cost of either performance or energy efficiency. In this paper, we discuss the trade-offs between energy efficiency and carbon efficiency in exploiting computing’s flexibility and show that blindly optimizing for energy efficiency is not always the right approach.
The War of the Efficiencies: Understanding the Tension between Carbon and Energy Optimization
In their paper they describe these four interventions in a different way (emphasis mine):
The key idea in increasing carbon efficiency is to exploit computing’s workloads flexibility by adjusting execution time (Temporal Shifting), speed (Scaling and Rate Shifting), and location (Spatial Shifting) according to the grid’s carbon intensity. In this paper, we highlighted
an inevitable tension between carbon and energy efficiency. We
explored the core mechanisms used in carbon-efficient computing
along with policies from the state-of-the-art in a wide range of
scenarios. The paper demonstrated qualitatively and quantitatively
that “striving for maximum energy efficiency is not always the most
sustainable (carbon-efficient) approach”.
There’s also a good 15 minute video now as well – HotCarbon’23: The War of the Efficiencies: Understanding the Tension between Carbon and Energy Optimization (Hanafy et al.)
Finding a way to make this memorable
I’m now thinking of it in these terms, and as ever, I’m trying to formulate it in terms of three things, so it’s easier to remember, and fits on a slide deck easily.
Schedule it – as in move the job through time. This would include scheduling in the future, and where possible, splitting a job up if it’s one that can be paused and restarted. You’re only introducing one big new concept at this point, and the pausing / restarting is optional.
Scale it – as in scale the resources allocated to the work. This would include the different mechanisms for doing more or less work on a given computer, now that you’ve introduced the idea that the carbon intensity can change over time. I think you might introduce this second, as it puts people back on familar ground, and intuitively, the idea of scaling up a job up or down to use more resources to change the speed at which you get through a given amount of work is one that developers are fairly familiar with now.
Migrate it – as in move it through space. Finally I’d introduce the concept of deploying the work to a different location. From an organisational point of view this is likely the most complex to implement, and I think that it would also be conceptually most effective once someone learning about this has some confidence about the first two of these interventions.
OK, so that’s my current thinking as as way to reduce this down to something that might be easy to remember – Schedule it, Scale it, and Migrate it.
Update: re-reading this post, the following might be clearer: Change the time, Change the speed, and finally Change the place.
Which of these feels more intuitive? I’d love to hear back if you’ve made it this far. As ever, I’m reachable along all the channels in the about page.
Comments
One response to “Options to make software greener without changing the code, and how to remember them”
@chris oh wow, I totally forgot I had hooked up my WordPress to post using activitypub. At least I know it works now I guess!Below is the full text of the post I wrote, about finding a mental model to think about carbon aware computing.Is there a way to share just a summary or except with the default masto plugin for WordPress ? It’s obnoxiously long in a mastodon client 😅