I’m sharing this post as it I think it helped me realise something I hadn’t appreciated til today.
I don’t build AI models, and to be honest, while I make sparing use of Github Co-pilot and Perplexity, I’m definitely not a power user.
My interest in them is more linked to my day job, and how their deployment or widespread use makes a fossil free internet 2030 more or less likely.
Anyway, this post is about the EU AI Act.
I’m going to post some text from the EU AI Act law, which became law across Europe earlier this year. See this high level summary of the law, for some extra context. It’s a big law in many ways, and the the text below is from Annex XI: Technical Documentation Referred to in Article 53(1), Point (a) – Technical Documentation for Providers of General-Purpose AI Models.
I’ve edited it for brevity and clarity to draw attention to the bits important to this post:
Section 1 – Information to be provided by all providers of general-purpose AI models
The technical documentation referred to in Article 53(1), point (a) shall contain at least the following information as appropriate to the size and risk profile of the model:
(snip)
A detailed description of the elements of the model referred to in point 1, and relevant information of the process for the development, including the following elements:
(snip)
(d) the computational resources used to train the model (e.g. number of floating point operations ), training time, and other relevant details related to the training;
(e) known or estimated energy consumption of the model. With regard to point (e), where the energy consumption of the model is unknown, the energy consumption may be based on information about computational resources used.
I had some dim awareness that training numbers had to be measured and reported, but I hadn’t read the text until this weekend, and I realised it doesn’t explicitly say training only.
Ok. it says known or estimated energy consumption of the model. What else might that include?
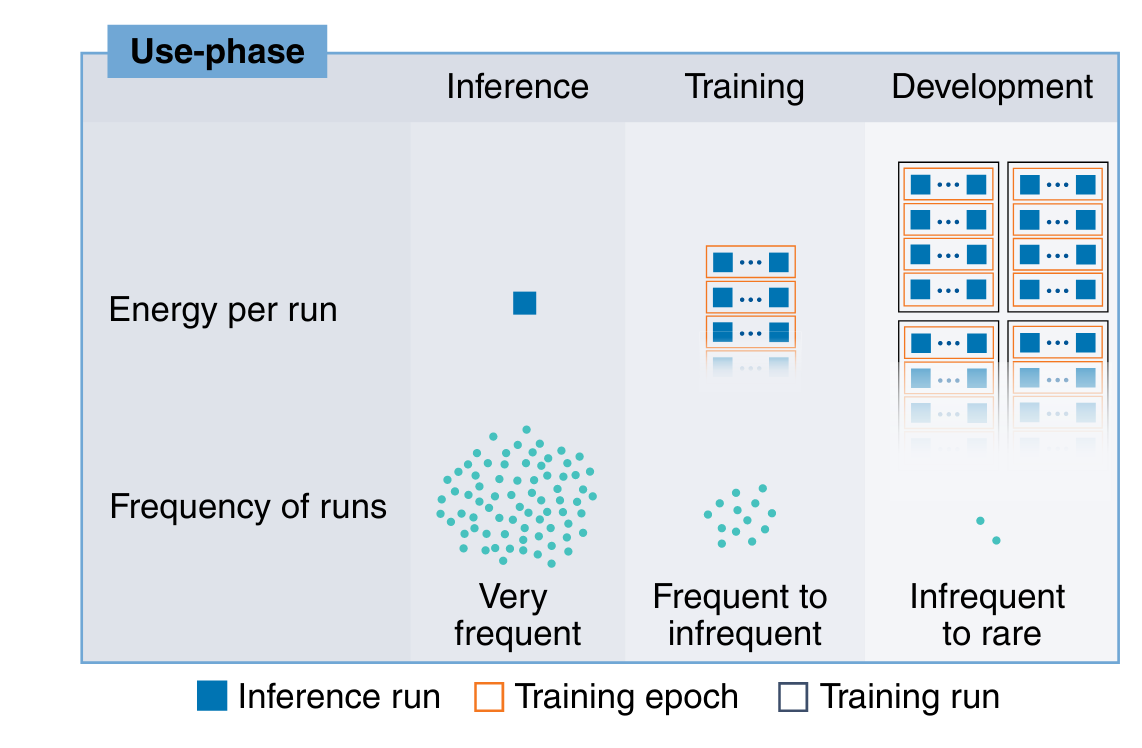
Let’s use a helpful diagram from a paper by some folks Climate Change AI, and friends, Aligning artificial intelligence with climate change mitigation. I read it last week and the diagram is looking at energy use associated with AI models – I think might help lay out why I think the text of the act might cover more than training.

As the paper details, there are multiple stages that use energy when using an AI model – there’s training and development which roughly correspends to making of the model, and then there’s inference, which is the actual use of the model.
Let’s break these down.
Training (or if you prefer, training and development)
As the diagram suggests, training is the stuff we’ve seen in the news a lot. In some models, you can see helpful model cards like this one for Meta’s Llama 3.1b:
Training Greenhouse Gas Emissions Estimated total location-based greenhouse gas emissions were 11,390 tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy, therefore the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
There’s even a table like this in the model card on Hugging Face:
| Training Time (GPU hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) | |
| Llama 3.1 8B | 1.46M | 700 | 420 | 0 |
| Llama 3.1 70B | 7.0M | 700 | 2,040 | 0 |
| Llama 3.1 405B | 30.84M | 700 | 8,930 | 0 |
| Total | 39.3M | 11,390 | 0 |
In theory, you might get super lucky and and get perfect results from a single training run when making a model. It’s more likely you’d need lots of training runs. This is why the diagram at the top, when showing energy per runs, shows a big load of training runs grouped together.
Inference
As I mentioned before, this is the other part, which is the actual use of the model, like when you might ask ChatGPT, or some other similar chatbot a question.
Here the energy use is smaller, but because it happens so often, in absolute terms it can be enormous. This is because there can be millions of people using AI models, each requiring inference to return a result.
The image I lifted below comes from an article in Nature about the AI Energy Star project, and it gives an idea of the energy usage for different kinds of inference:

Why you might require meaningful numbers on both inference and training
This is definitely not a perfect comparison, but let’s image an AI model is a car for a second, just to make this easier.
Training and developing the model is a bit like making the car – there’s obviously an environmental impact to making a car, and given we live on a planet with finite carrying capacity, we ought to know what it is.
Inference for a model is a bit like driving that car – if you are going to use the car, you probably ought to know how efficient it is, or how dirty the exhaust is. We have these with miles per gallon figures for fuel efficiency, and grams of CO2 per kilometer for carbon emissions too.
Pointers welcome
As I said before, my experience working with AI is limited, so these might be really basic questions, but they might also be pertinent ones too. If you know, I’d love to hear from you – I list the best ways to reach me on me about page. Ta!